
网达软件通过多年来在视频采集、处理、理解及制作等领域的技术积累,拥有丰富的媒体视频及行业视频多场景下的AI赋能实践经验,基于视觉大模型技术以及丰富的算法开发能力,实现视频内容的快速识别、定位、编辑与分发;也可以结合行业场景实际需求,精准识别视频中的人员违规、车辆违规、设备和环境异常等安全隐患,具备融合感知、多视角联动、预警联动、快速处置、多维分析等统一管理能力,助力企业实现安全生产的可测可管可控。
以人体为核心的行为大模型
网达软件基于积累的海量业务数据,可以实现各数据之间的更细粒度的对齐,通过引入显式和隐式知识对数据进行有效筛选,构造了丰富的训练集微调度基座大模型,除用于增强人体视觉特征的基础数据,还开发了适配各类下游任务场景特点指令微调数据,进一步提升大模型识别新数据属性的能力,以适应特定的任务和场景需求。
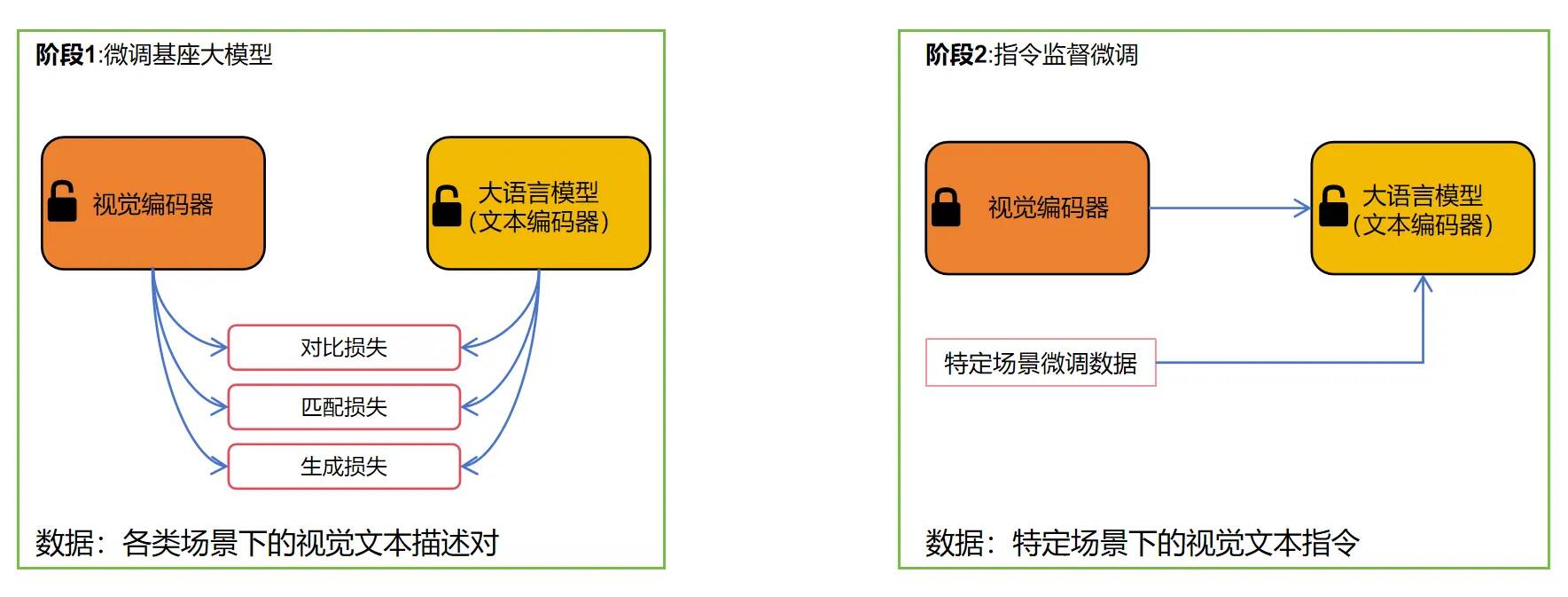
高效训练与算法优化能力
网达软件通过现场视频数据和结构化知识进行大模型的预训练,通过设计基于自监督学习的预训练任务形成更适合的算法模型,利用多视觉大模型技术,通过对视频中的行为、时序动作、时空动作进行检测,从而更为准确地对视频中人物、车辆动作特征进行识别,并提升在复杂场景(天气、光照、温湿度)下的泛化能力。
多源融合感知
随着感知数据类型的日益丰富,利用图像、视频、红外、雷达等多类型传感数据进行融合,形成更大规模的视频-图像-感知预训练数据,进一步提升模型的表达能力和应用范围。基于大模型深度学习框架,实现融合多视角视觉、多波段光学、多频谱振动等多元感知数据分析,实现复杂场景精准预警。
云边协同,多平台多架构实现
针对不同应用场景与算力需求特征,提供“视觉大模型+语言大模型”与“视觉大模型+场景小模型”两种架构选型,在云端大算力平台及边端有限算力平台上针对不同的应用场景进行模型适配压缩和推理加速,扩展创新应用。
应用场景
1. 智能视频检索
支持以图像、自然语言等形式进行目标检索,快速反向查找特定人物及事件的时空轨迹。
2. 安全生产监督
准确识别监控视频内人员及车辆的安全行为风险,全视场下24小时助力安全监督管理。
3. 窄带高清
基于对视频内容及场景理解下的视频流编码参数调优,从而实现低码率条件下ROI内容的高清晰度输出。
视觉大模型以其卓越的技术性能和广泛的应用前景正逐步成为推动各行业智能化转型的重要力量。随着技术的不断进步和应用场景的不断拓展,在未来发挥更加重要的作用,为人类社会带来更多的便利和创新。
人工智能技术网 倡导尊重与保护知识产权。如发现本站文章存在版权等问题,烦请30天内提供版权疑问、身份证明、版权证明、联系方式等发邮件至1851688011@qq.com我们将及时沟通与处理。!:BB贝博艾弗森官方网站 > 人工智能产业 > AI大模型 » 网达视觉大模型助力行业AI快速落地
 中国石油发布330亿参数昆仑大模型,
中国石油发布330亿参数昆仑大模型, 昇腾与昇思原生,助力智谱打造自主创
昇腾与昇思原生,助力智谱打造自主创 赋能未来运维:大模型驱动的容器系统
赋能未来运维:大模型驱动的容器系统 智能算力产业优秀实践,曙光All In!
智能算力产业优秀实践,曙光All In! 车路云一体化或将补足大模型“上车
车路云一体化或将补足大模型“上车 爱诗科技发布PixVerse V2,更快更长
爱诗科技发布PixVerse V2,更快更长 科大国创星云大模型入选“2024年中
科大国创星云大模型入选“2024年中 大模型时代下,构建安全可靠大数据底
大模型时代下,构建安全可靠大数据底